前面说过,大多数语言都提供了散列表实现,你不用知道如何实现它们。有鉴于此,我就不再过多地讨论散列表的内部原理,但你依然需要考虑性能!要明白散列表的性能,你得先搞清楚什么是冲突。本节和下一节将分别介绍冲突和性能。
首先,我撒了一个善意的谎。我之前告诉你的是,散列函数总是将不同的键映射到数组的不同位置。
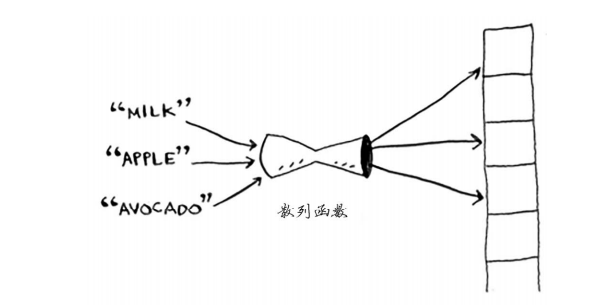
实际上, 几乎不可能编写出这样的散列函数。我们来看一个简单的示例。假设你有一个数组,它包含26个位置。
AMY :大名鼎鼎md5和sha就是散列算法,冲突概率几乎为0,但是在目前的密码学技术上严格意义上来说应该是没有这样的散列函数的。
而你使用的散列函数非常简单,它按字母表顺序分配数组的位置。
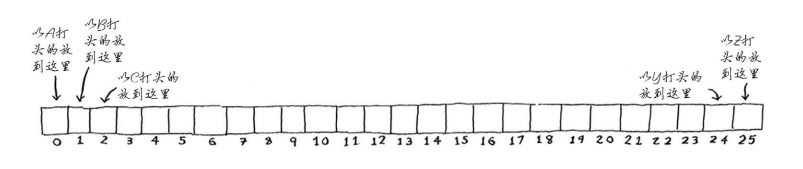
你可能已经看出了问题。如果你要将苹果的价格存储到散列表中,分配给你的是第一个位置。
接下来, 你要将香蕉的价格存储到散列表中,分配给你的是第二个位置。
一切顺利!但现在你要将鳄梨的价格存储到散列表中,分配给你的又是第一个位置。
不好,这个位置已经存储了苹果的价格!怎么办?这种情况被称为冲突(collision) :给两个键分配的位置相同。这是个问题。如果你将鳄梨的价格存储到这个位置,将覆盖苹果的价格,以后再查询苹果的价格时,得到的将是鳄梨的价格!冲突很糟糕,必须要避免。处理冲突的方式很多,最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。
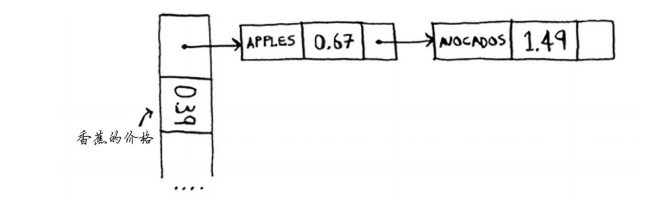
在这个例子中, apple和avocado映射到了同一个位置,因此在这个位置存储一个链表。在需要查询香蕉的价格时,速度依然很快。但在需要查询苹果的价格时,速度要慢些:你必须在相应的链表中找到apple。如果这个链表很短,也没什么大不了——只需搜索三四个元素。但是,假设你工作的杂货店只销售名称以字母A打头的商品。
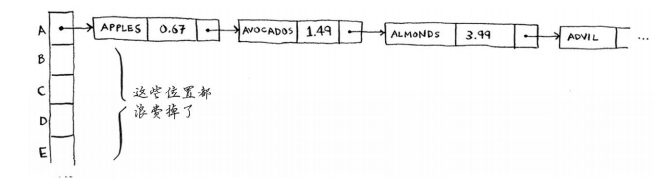
等等! 除第一个位置外,整个散列表都是空的,而第一个位置包含一个很长的列表!换言之,这个散列表中的所有元素都在这个链表中,这与一开始就将所有元素存储到一个链表中一样糟糕:散列表的速度会很慢。
这里的经验教训有两个。
- 散列函数很重要。前面的散列函数将所有的键都映射到一个位置,而最理想的情况是, 散列函数将键均匀地映射到散列表的不同位置。
- 如果散列表存储的链表很长,散列表的速度将急剧下降。然而, 如果使用的散列函数很好,这些链表就不会很长。
散列函数很重要,好的散列函数很少导致冲突。那么,如何选择好的散列函数呢?这将在下一节介绍!