假设你管理着网站Reddit。每当有人发布链接时,你都要检查它以前是否发布过,因为之前未发布过的故事更有价值。
又假设你在Google负责搜集网页,但只想搜集新出现的网页,因此需要判断网页是否搜集过。
在假设你管理着提供网址缩短服务的bit.ly,要避免将用户重定向到恶意网站。你有一个清单,其中记录了恶意网站的URL。你需要确定要将用户重定向到的URL是否在这个清单中。
这些都是同一种类型的问题,涉及庞大的集合。
给定一个元素,你需要判断它是否包含在这个集合中。为快速做出这种判断,可使用散列表。例如, Google可能有一个庞大的散列表,其中的键是已搜集的网页。
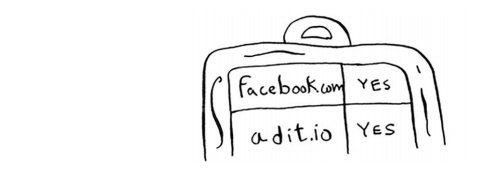
要判断是否已搜集adit.io,可在这个散列表中查找它。
adit.io是这个散列表中的一个键,这说明已搜集它。散列表的平均查找时间为O(1),即查找时间是固定的,非常好!
只是Google需要建立数万亿个网页的索引,因此这个散列表非常大,需要占用大量的存储空间。 Reddit和bit.ly也面临着这样的问题。面临海量数据,你需要创造性的解决方案!