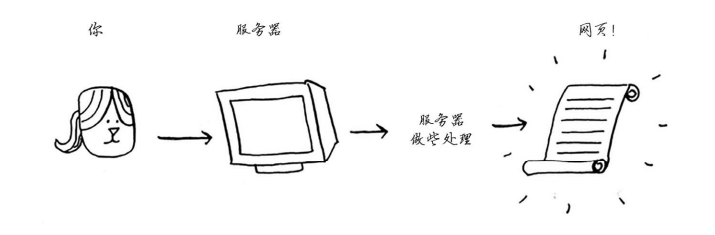
来看最后一个应用案例:缓存。如果你在网站工作,可能听说过进行缓存是一种不错的做法。下面简要地介绍其中的原理。假设你访问网站facebook.com。
- 你向Facebook的服务器发出请求。
- 服务器做些处理,生成一个网页并将其发送给你。
- 你获得一个网页。
例如, Facebook的服务器可能搜集你朋友的最近活动,以便向你显示这些信息,这需要几秒钟的时间。作为用户的你,可能感觉这几秒钟很久,进而可能认为Facebook怎么这么慢!另一方面, Facebook的服务器必须为数以百万的用户提供服务,每个人的几秒钟累积起来就相当多了。为服务好所有用户, Facebook的服务器实际上在很努力地工作。有没有办法让Facebook的服务器少做些工作,从而提高Facebook网站的访问速度呢?
假设你有个侄女,总是没完没了地问你有关星球的问题。火星离地球多远?月球呢?木星呢?每次你都得在Google搜索,再告诉她答案。这需要几分钟。现在假设她老问你月球离地球多远,很快你就记住了月球离地球238 900英里。因此不必再去Google搜索,你就可以直接告诉她答案。这就是缓存的工作原理:网站将数据记住,而不再重新计算。
如果你登录了Facebook,你看到的所有内容都是为你定制的。你每次访问facebook.com,其服务器都需考虑你感兴趣的是什么内容。但如果你没有登录,看到的将是登录页面。每个人看到的登录页面都相同。 Facebook被反复要求做同样的事情:“当我注销时,请向我显示主页。”有鉴于此,它不让服务器去生成主页,而是将主页存储起来,并在需要时将其直接发送给用户。
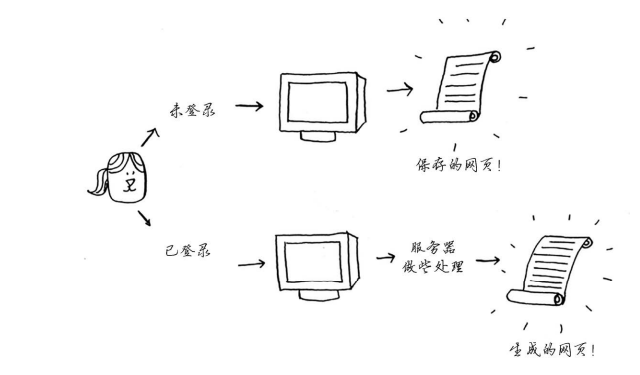
这就是缓存,具有如下两个优点。
- 用户能够更快地看到网页,就像你记住了月球与地球之间的距离时一样。下次你侄女再问你时,你就不用再使用Google搜索,立刻就可以告诉她答案。
- Facebook需要做的工作更少。
缓存是一种常用的加速方式,所有大型网站都使用缓存,而缓存的数据则存储在散列表中!
Facebook不仅缓存主页,还缓存About页面、 Contact页面、 Terms and Conditions页面等众多其他的页面。因此,它需要将页面URL映射到页面数据。
当你访问Facebook的页面时,它首先检查散列表中是否存储了该页面。
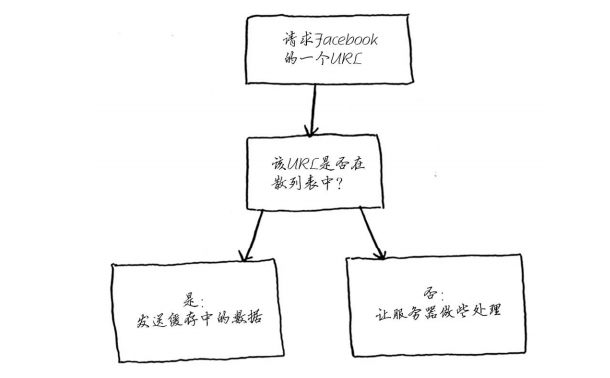
具体的代码如下。
cache = {}
def get_page(url):
if cache.get(url):
return cache[url]#返回缓存的数据
else:
data = get_data_from_server(url)
cache[url] = data#先将数据保存到缓存中
return data
仅当URL不在缓存中时,你才让服务器做些处理,并将处理生成的数据存储到缓存中,再返回它。这样,当下次有人请求该URL时,你就可以直接发送缓存中的数据,而不用再让服务器进行处理了。